나는 여전히 대학원에서 인공지능 반도체 회로 설계를 하고 있다.
현대에 들어서는 반도체 공정 scaling의 한계에 도달했다는 이야기가 종종 언론을 통해서 들리는 것을 다들 알고 있을 것이다. 현재까지 개발되어 상용화된 공정들을 보면 3 nm 까지는 나와있고, 1.4 nm 공정까지 로드맵이 나와 있던 것으로 기억을 한다.
개인적인 체감으로는 반도체 공정의 scaling은 28 nm 공정을 기점으로 더 이상 scaling이 빠르지 않고, cost effective하지 않게 된 것 같은 느낌이 있다. 미세 공정이라고 하더라도, 결국 트랜지스터가 가질 수 있는 최소 선폭의 길이를 얼마나 줄일 수 있는지가 중요 관점이다.
반도체 회로는 트랜지스터만으로 구성되지 않는다. 트랜지스터들을 연결해서 회로를 만들기 위해서는 메탈라인이 필요한데 IR drop을 고려해서 메탈의 면저항을 최소화하기 위해 어느정도 두껍게 쌓는다. 이로 인하여 메탈 라인의 선폭은 무지막지하게 작아질 수 없고, 메탈 라인들간의 간격을 무작정 줄일 수도 없는 것이다.
인공지능 기술을 구성하는 key operation은 matrix-vector multiplication으로, 간단한 multiply-and-add (MAC) 연산으로 구현된다. MAC 연산 자체의 연산 복잡도는 높지 않다. 그럼에도 불구하고 폰 노이만 컴퓨팅 구조가 한계를 보이는 것은 그 연산의 수행 횟수에 원인이 있다. 인공신경망에서는 MAC 연산이 매우 많이 수행된다. MAC 연산을 가속하기 위해 수 만 개의 CUDA 코어를 갖고 있는 GPU를 활용하여 연산을 가속하는 방식이 주로 사용되지만, 이는 임시방편에 불가하다.
트랜지스터 집적도를 향상시키기 위한 공정 기술 혁신은 이제 3D integration 위주로 최신 연구개발들이 진행되고 있고, 컴퓨팅 구조에 대한 연구들에서는 폰 노이만 구조를 벗어난 새로운 구조들에 대한 연구가 되고 있는 것이다. 이러한 연구 트렌드는 인공지능 기술이 발전함에 따라 더욱 더 가속되고 있다. 중앙 집중화된 ALU를 통해 연산을 수행하는 전통적인 컴퓨팅 구조는 인공지능 시대에 들어서 그 한계를 보이고 있다.
인공지능 응용에서 폰 노이만 구조를 벗어나 MAC 연산을 가속하기 위한 방법들은 다양하게 제시되어 왔다. 디지털에서는 approximation computing, LUT 기반의 컴퓨팅, stochastic computing 등 다양한 연구들이 수행되고 있지만 memory bandwidth 의존에서는 벗어날 수 없다. 인공지능 연산에서 massive parallelism을 구현하기 위해서는 메모리 내에서 연산이 수행될 필요가 있었다. 일례로 생물학적 시냅스를 모방한 뉴로모픽 컴퓨팅, spiking neural network 연구 등이 있지만 spiking time dependency plasticity (STDP) 같은 학습 방법이 존재함에도 불구하고 인공신경망 학습이 역전파 알고리즘을 따라오지 못하는 문제가 있어 한계가 존재했었다.
이에 대한 대안으로 Processing in memory (PIM), in-memory computing (IMC), compute-in-memory (CIM), near-memory computing와 같은 컴퓨팅 시스템에 대한 연구가 되고 있다. PIM, IMC, CIM은 어느정도 비슷한 맥락을 갖는 단어들이다. 말 그대로 메모리 내 연산을 수행하는 기술들이다. 이러한 연구들은 아날로그 컴퓨팅으로 구현될 수도 있고, 디지털 컴퓨팅으로 구성될수도 있다. 또는 두 가지가 혼재되어 있을 수도 있다. 폰 노이만 구조를 벗어나고자 하는 시도는 아주 도전적이고 실제로 어느정도 성과를 보이고 있다. 그렇다면 왜 하필 메모리가 차세대 컴퓨팅 기술의 핵심으로 부각되는 것일까?
나의 경우에는 PIM, IMC, CIM에 해당하는 연구를 주로 하고있다. PIM은 말 그대로 메모리 내에서 연산을 수행하는 연산 기술로, 메모리 셀 자체를 손을 봐서 간단한 로직 연산들을 내장하는 것이 주 연구 방향이다. 이렇게 추가된 기능들을 이용하여 메모리 어레이에 가중치 행렬을 대응시켜 어레이의 읽기 동작 한번만으로 MAC연산을 구현할 수 있다.
반면 near-memory는 일반적인 메모리 주변 회로에 연산 유닛을 둬서 데이터 전송에서의 에너지를 줄이고 메모리 어레이 자체의 bandwidth를 최대한 활용하는 것이 주된 연구 관점이다. 혹자는 이런 궁금증이 생길 수 있다. "메모리 어레이 주변에서 연산을 하는 것이 얼마나 효율적이길래 이런 연구를 할까?"
위의 질문에 대한 답은 아래의 테이블을 통해서 할 수 있을 것 같다.
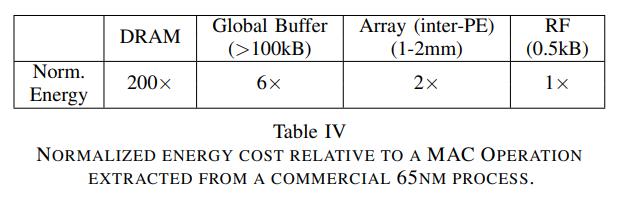
위의 테이블은 파운드리 65 nm 공정에서 각 계층 구조 접근에 필요한 에너지를 상대적으로 비교한 표이다. 표를 보면 DRAM은 에너지가 특히 많이 드는 것을 볼 수 있다. 위의 표에는 따로 기재되어 있지는 않지만 칩 외부로 가면 갈수록 data access time이 길어지는 문제가 존재한다. DRAM에 데이터를 읽고 쓰기 위해서는 칩 내/외부의 수 많은 버스 신호들을 driving 해야하기 때문에 버스에서의 에너지 소모와 통신 지연이 많이 발생한다.
인공신경망 기술은 memory bound한 task들이 많기 때문에 폰 노이만 구조를 기반으로 하는 CPU나 GPU를 통해 학습을 수행할 경우 위의 동작이 엄청나게 많이 수행되어 에너지 효율이 나쁘다. 폰 노이만 컴퓨팅 구조에서 DRAM에서 데이터를 읽어 연산을 한 이후 다시 DRAM에 저장하는 task를 생각해보자. 한 번의 ALU 연산을 위해서 DRAM -> ALU register, ALU register -> DRAM의 data access가 발생한다. Systolic array 어레이를 사용하더라도, 결국은 데이터를 DRAM에서 가져와야 하기 때문에 연산 pipeline을 아무리 최적화해도 어느 수준 이상의 연산 에너지 효율을 달성하기는 어렵다.
이러한 관점에서 near memory computing이 관심을 받고 있고, 이러한 연구들은 많은 경우 DRAM을 타겟으로 연구가 수행된다.
예를 들어 아래와 같이 연속적인 더하기 연산을 수행한다고 가정해보자.
add C, A, B
store C
add F, D, E
store F
add G, C, F
위의 동작을 수행할 때 DRAM에서의 메모리 접근을 간단하게 기술하면 다음과 같이 설명할 수 있다.
1. A라는 데이터를 DRAM에서 ALU 레지스터로 가져온다.
2. B라는 데이터를 DRAM에서 ALU 레지스터로 가져온다.
3. ALU 연산 결과 C를 DRAM에 저장한다.
4. D라는 데이터를 DRAM에서 ALU 레지스터로 가져온다.
5. E라는 데이터를 DRAM에서 ALU 레지스터로 가져온다.
6. ALU 연산 결과 F를 DRAM에 저장한다.
7. C라는 데이터를 DRAM에서 ALU 레지스터로 가져온다.
8. F라는 데이터를 DRAM에서 ALU 레지스터로 가져온다.
G = A + B + D + E라는 연산 결과를 ALU 레지스터에 갖고 있기 위해 벌써 8번의 메모리 접근 과정이 필요하다.
만일 우리가 near memory computing 기술을 이용해서, DRAM 메모리 die에 간단한 사칙연산 또는 로직 연산을 수행할 수 있는 연산기를 넣을 수 있다면 이러한 메모리 억세스를 줄일 수 있다. DRAM에서 raw 데이터가 아닌 더하기 연산 결과를 가져올 수 있다고 가정해보면 앞선 연산을 다음과 같이 표현할 수 있다.
1. A+B 결과를 DRAM에서 ALU 레지스터로 가져온다.
2. D+E 결과를 DRAM에서 ALU 레지스터로 가져온다.
이렇듯 memory die 내에서 로직 연산을 구현하게 될 경우, 동일한 동작을 수행하기 위한 메모리 접근을 줄일 수 있다.
이는 메모리 접근을 줄이는 것에서 더 나아가 동일한 동작 수행에 8번의 메모리 접근을 필요로 하던 것을 2번으로 줄였기 때문에 memory bandwidth가 4배 증가한 것과 동일한 효용성을 갖는다.
인공지능 반도체에서 1) 빠른 연산 속도, 2) 높은 연산 에너지 효율, 3) high bandwidth가 가장 중요한 figure of mertic (FoM)이라고 할 수 있다. 처음에 잠시 언급한 PIM 기술이나 near-memory computing이나 결국 접근 방식에 있어 차이가 있을 수 있지만 FoM을 개선하기 위한 방법론 중에 하나라고 이해하면 요즘 연구 동향을 이해하는 데 있어 도움이 될 것이라고 생각된다. 그리고 연구 방향이 이런 식으로 흘러가는 데에는 반도체 공정 기술 scaling의 한계 및 인공지능 기술의 급성장이 있다고 할 수 있다.
댓글